
Welcome:
Login
|
Sign Up
|
About CircleID
Follow:
|
|
|


|
||
|
||
Just in time for ICANN‘s 44th meeting next week, a new Internet Draft has turned up, purporting to fix the centralization of the DNS. The draft has received some attention, including an article in PC World. It isn’t entirely clear what the real purpose of the draft is, but it is hard to credit the notion that it is solving any technical problem.
Without examining the reasons why the draft exists, I want to debunk a claim in it. It pretends to get rid of the central root of the DNS, but the idea that you can get rid of the root is a simple technical error.
What is the AIP draft?
Internet Drafts are proposals that could become part of the RFC series. The RFC series is, among other things, the way in which Internet standards get published. Internet standards go through a long process at the Internet Engineering Task Force (IETF) before they are adopted.
While it is hard to get an RFC published, anyone at all can publish an Internet Draft. All you need to do is format some text in a particular way and upload the draft to the Internet Draft repository. People often pretend that having an Internet Draft makes something “a draft RFC”. That isn’t true.
You could write an Internet Draft about Moby Dick, whether Pluto is really a planet or about the personal grooming habits of your office mates, and upload it. None of these would have the faintest hope of being published as RFCs. For the same reasons, lots of bad technical ideas get expressed in Internet Drafts and never become RFCs.
Around the IETF, the ease of proposing bad ideas in Internet Drafts is often seen as a virtue. Every now and then, a wild idea turns out to be a good one rather than just silly. You’ll never know which it is, however, unless you discuss it with others.
The particular draft we are talking about—“DNS Extension for Autonomous Internet (AIP)”—is a draft that offers a mechanism to replace the DNS root. It contains a wild idea.
What’s a DNS root and why do I care?
If you’re a reader here, you’ll most likely know that the Domain Name System provides, among other things, the mechanism by which humans can remember where things are located on the Internet. Machines talk to each other in numbers and every machine on the Net has at least one address (an IP address). Among its other functions, the DNS provides a way to map names to those IP addresses, so that instead of having to remember 2600:2001:0:3::106 you can just remember ‘www.dyn.com’.
The DNS is, formally, a hierarchy or tree structure. Each whole (“fully qualified”) DNS name identifies a particular place in the tree. The spots in the tree (“nodes”) are identified by the “labels” in the name—roughly, the things between the familiar “dots” of an Internet name. For reasons that are interesting to geeks but otherwise really boring, the root label is 0 bytes long and is therefore invisible. Formally then, the machine hosting Dyn’s home page is named ‘www.dyn.com.’ (notice the final dot), but because everyone uses one root, we just leave the final dot off. It is possible to draw a picture of the DNS (or, in this case, part of it) that looks like this:
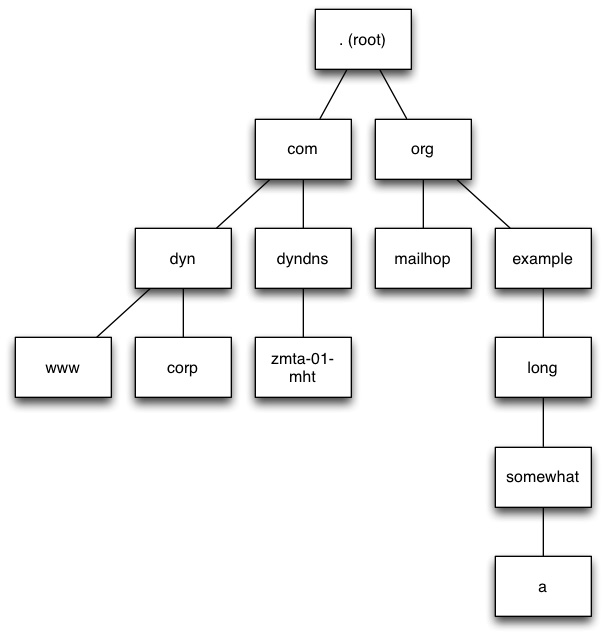
As you can see, it contains the names ‘www.dyn.com.’, ‘corp.dyn.com.’, ‘zmta-01-mht.dyndns.com.’, ‘mailhop.org.’ and ‘a.somewhat.long.example.org.’ Every one of them ends at the same root. If you had never looked up a domain name before, you would start at the root and work your way down until you found the last label. When you’re starting from nothing, you start at the root; there’s no other way to do it.
What does the AIP Internet Draft propose?
The draft claims that the single DNS root is a liability for two reasons. First, it claims that there is a scaling problem with the single root—that the existing root cannot possibly grow to meet the needs of the Internet. Second, it claims that there is a problem of centralized control with the current architecture. Having identified these issues, it makes a proposal to break the name space into different segments that will automatically apply to lookups on the Internet. The authors call this the “Autonomous Internet”.
The first issue to deal with is the claim that the existing root system won’t scale. There is no reason whatsoever to believe it. Even if ICANN’s wildest expansion plans are achieved, there is no reason to believe that the root zone will grow to more than a few thousand names. The .com zone has 80 million names in it and is serving them all without any trouble. There is also no evidence to believe that the root name servers couldn’t handle more traffic: the root server system is massively overprovisioned.
So we are thrown back on the idea that the single root zone and set of root name servers represent a point of central control and that this control should be broken by creating the Autonomous Internet.
How is the Autonomous Internet supposed to work?
The idea is that the different parts of the Internet name space are broken up into autonomous segments. Each autonomous portion has a copy of all the names in the other portions, but the portions operate independently. So, if we imagine two portions “A” and “B”, it looks a little like this:
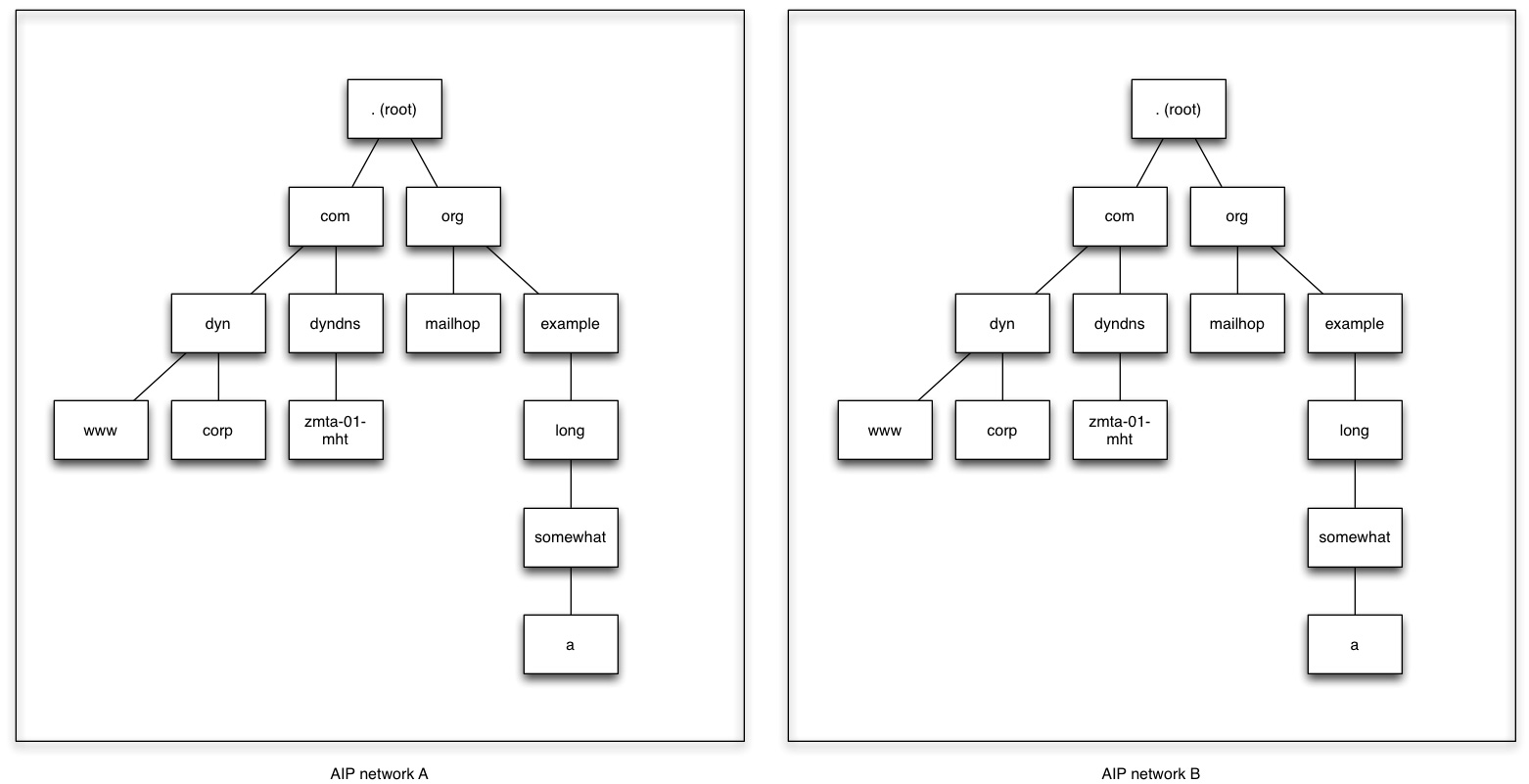
Obviously then, if you are in network A and you look up ‘www.dyn.com’, there is no problem: you go to ‘www.dyn.com’ in network A (which we can designate ‘www.dyn.com.A.’). But what if you are in network B? Since these are autonomous networks, there are only two possibilities:
If the first of these is true, then we are no longer talking about the Internet at all, but about a bunch of separate and private networks. This would be a giant step backwards to the days of services like CompuServe and GEnie where you had to know what network someone was on and join that network just to communicate with them. All of the innovation and benefit that we get from the universality of the Internet would be lost. That seems undesirable, so the draft does not propose it.
Instead, AIP proposes the second option. When you want to go to something in the other AIP network, you add that network to the name. But this means the AIP approach does not replace the single DNS root at all. AIP just augments the existing root with a “super-root” that contains the names of the individual allowed autonomous networks. If you have never looked anything up, you first have to start by deciding whether you are in A or in B. Then you work your way down.
AIP just adds one more level to identify the sub-tree of the individual autonomous network. The DNS is still a tree, and the tree has one root. This is true by definition. It’s not a political problem; it’s a fact about math. Therefore, the actual picture of the AIP proposal is not the previous diagram (which is roughly what is in the draft), but this one:

And of course, since there is a new root, someone has to decide who is in that new root and what the names inside the new root are. So to get rid of the root, we have to create a new root that does all the things the old root does! The AIP draft acknowledges this and proposes to create a new registry function at IANA to manage the new root.
What problem are the authors trying to solve?
It is hard to say what the AIP draft is actually trying to solve if it isn’t trying to break up the Internet and doesn’t actually get rid of the root. It does offer to create a new problem in that people will have to come together to re-invent the processes for allocating names in the new root. Do we really want to go through inventing ICANN all over again? In any case, the AIP draft is not a proposal that solves any technical problem the Internet has and it does not actually do what it says it sets out to do.
Sponsored byIPv4.Global

Sponsored byWhoisXML API

Sponsored byRadix

Sponsored byVerisign

Sponsored byVerisign

Sponsored byDNIB.com

Sponsored byCSC


A World-Renowned Source for Internet Developments. Serving Since 2002.