
Welcome:
Login
|
Sign Up
|
About CircleID
Follow:
|
|
|

|
||
At the ICANN 81 meeting in Istanbul on 10 November 2024, I gave a presentation about the DNS Root Server System, in an effort to increase understanding of the Root Server System (RSS) and Root Server Operators (RSOs). The talk was intended for the members of the ICANN Governmental Advisory Committee (GAC), but much of this explanation may be of interest to general audiences.
DNS uses human-readable names—commonly called domain names—to find numerical computer addresses. Humans can remember and understand names like www.amazon.com, while computers need IP addresses like 18.239.62.181. DNS is what tells us that www.amazon.com is at 18.239.62.181. The numbers can and do often change, while the human-readable names stay the same.
Connected devices on the Internet—computers, phones, printers, refrigerators, and so on—need DNS to be able to find other connected devices. When your smart fridge wants to send an alert to your phone to tell you you’re out of milk, that requires the DNS. But how do all the devices know where to find each other? Each device is able to ask the DNS questions about domain names, and the answers are IP addresses.
What are the benefits of DNS? The obvious one is that names are much easier for humans to remember than strings of numbers. But equally important is that the service becomes very portable; the addresses/hardware/platform/location/anything else can be changed, but as long as the name stays the same it will still be findable. The DNS is also a huge distributed network that’s remarkably easy to use. It is a flexible, delegated database that includes hundreds of millions of directories arranged in what is arguably the world’s largest distributed database.
So that’s DNS in a nutshell, but obviously it’s significantly more complicated in practice.
Devices get addresses from address resolvers, of which there are millions in the world. Resolvers can find and read what we might think of as the Internet’s “phone books,” which are actually authoritative servers that are held by organizations that each manage a portion of the Internet. Each of these authoritative servers contains the zone content, or address information, for all of the domains it controls.
To put it simply, DNS consists of devices asking questions like “What is the number for www.amazon.com?” and receiving the response “The number for www.amazon.com is (at the moment) 18.239.62.181.” These types of questions happen about 500 trillion times per day, and are answered in milliseconds by the resolvers.
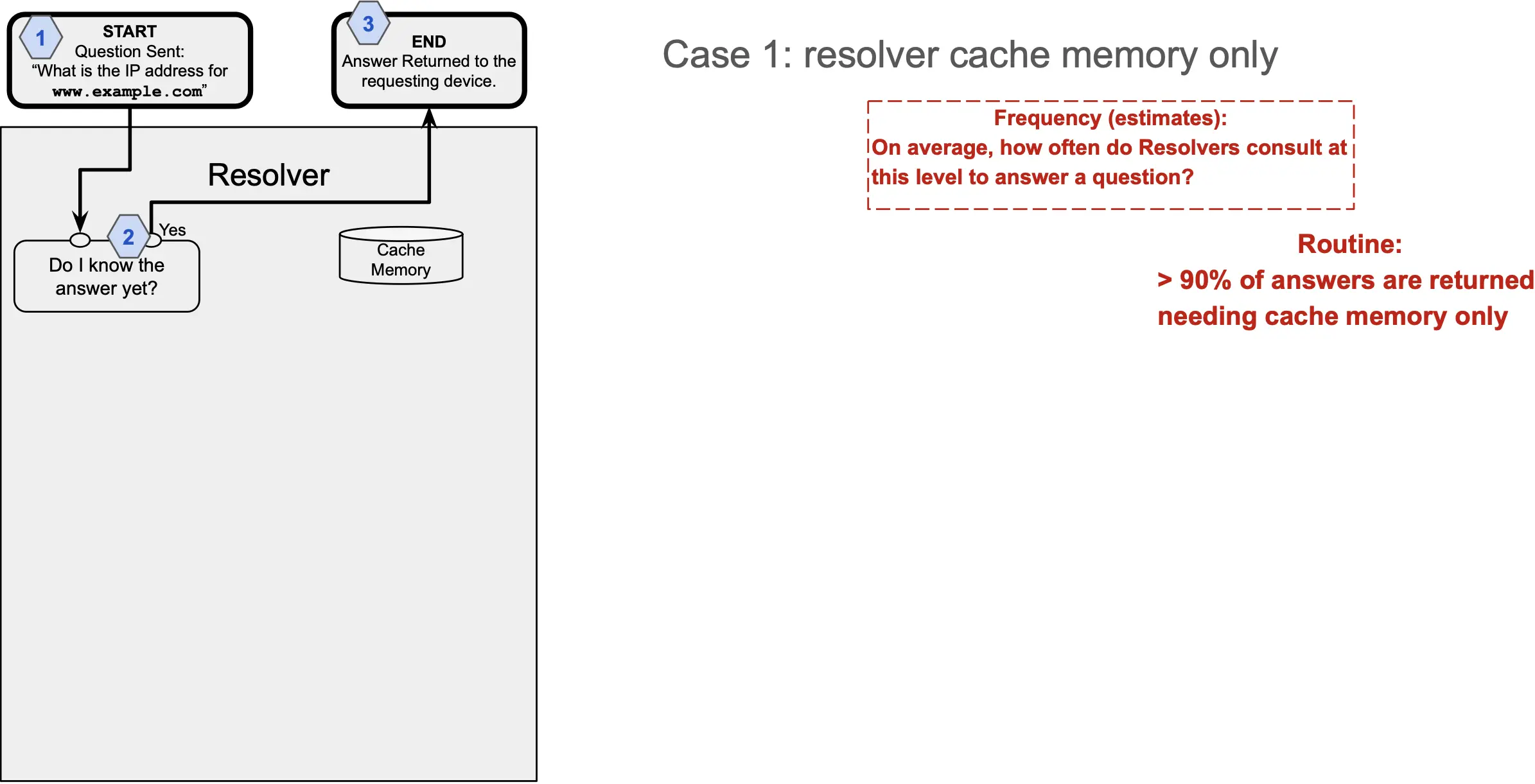
Normally, the resolvers remember what information they’ve asked for from the authoritative servers, and they hold that information for future queries. This is called “caching.” But sometimes, the resolver needs to learn a new number or confirm an old one.
Let’s step through the layers of the process and see how DNS works for the fictitious location www.example.com, depending on how much information a resolver needs:
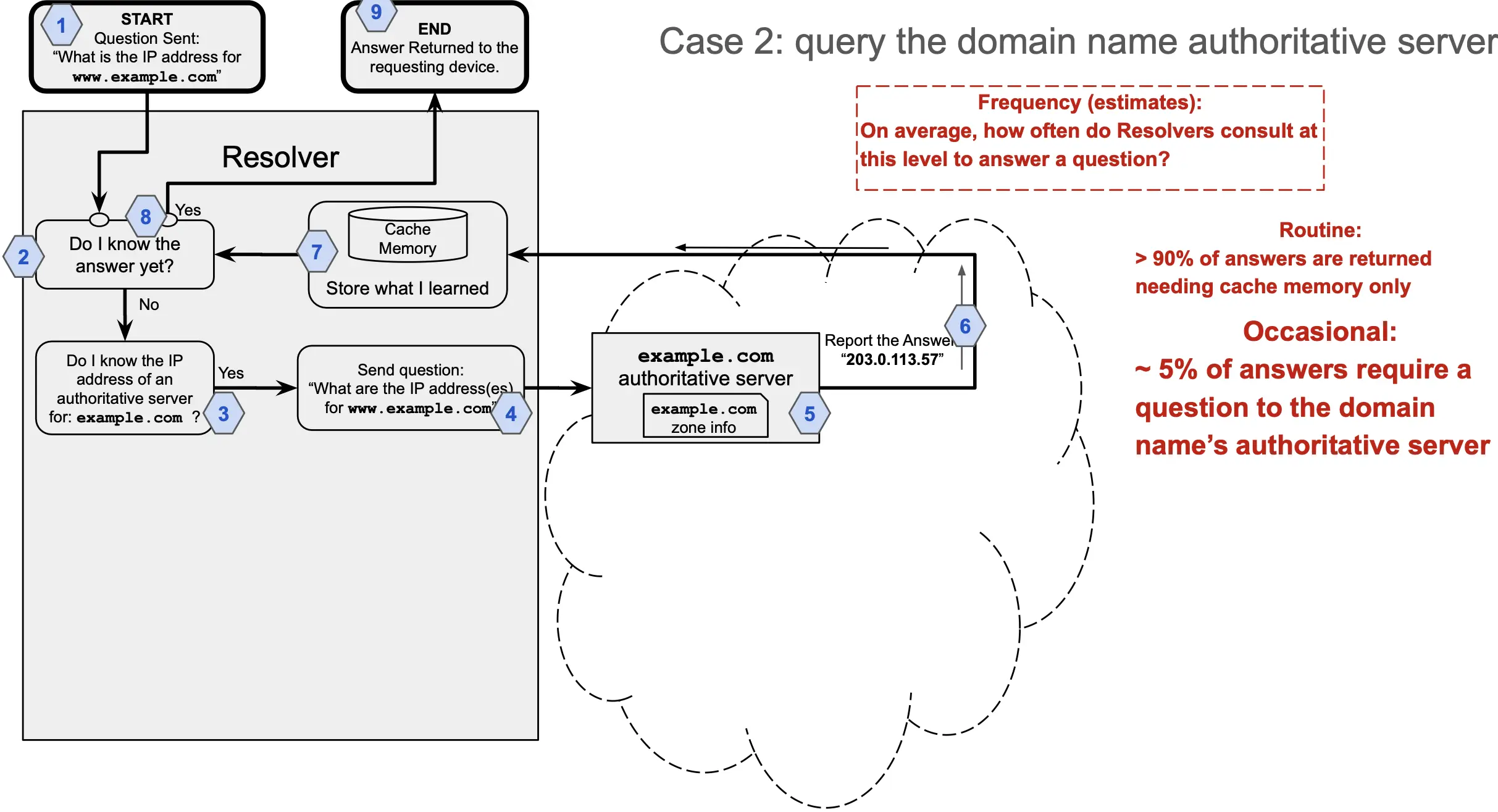
Case 2: The resolver has cached information about example.com, so it asks only the domain name’s authoritative server about where to find www.
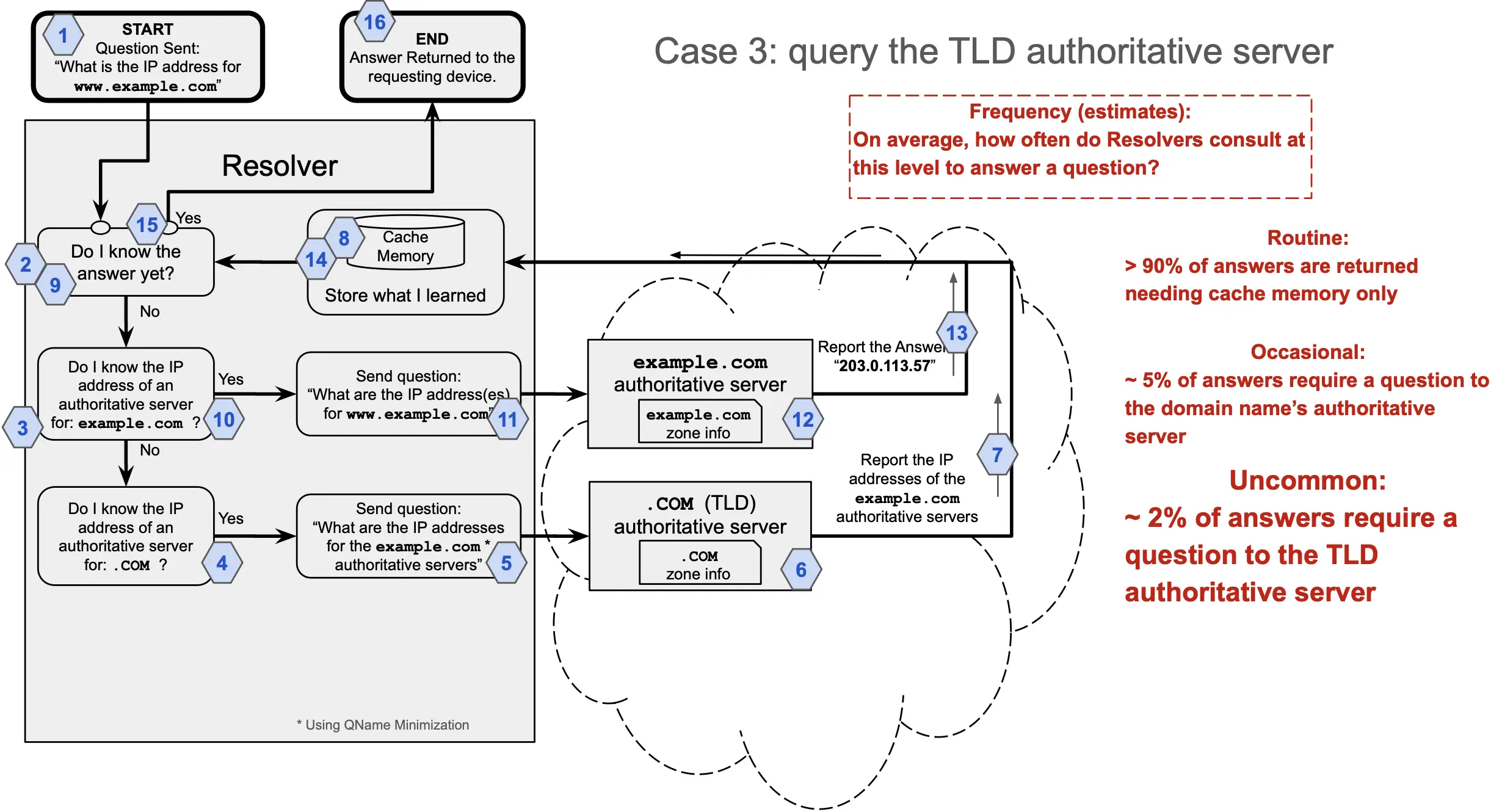
Case 3: The resolver doesn’t have information about www or example, but it knows where to get information about .com, a Top-Level Domain (TLD). It asks the TLD’s authoritative server for the location of example.com, and then that domain name’s authoritative server for the IP address of www.
Case 4: If the resolver is brand new and has no information cached in its memory, it needs to begin filling its memory cache. It starts by querying the Root Server System (RSS) to find out where to get information about .com, then asks the TLD authoritative server about example, and then queries the domain name’s authoritative server for the location of www.
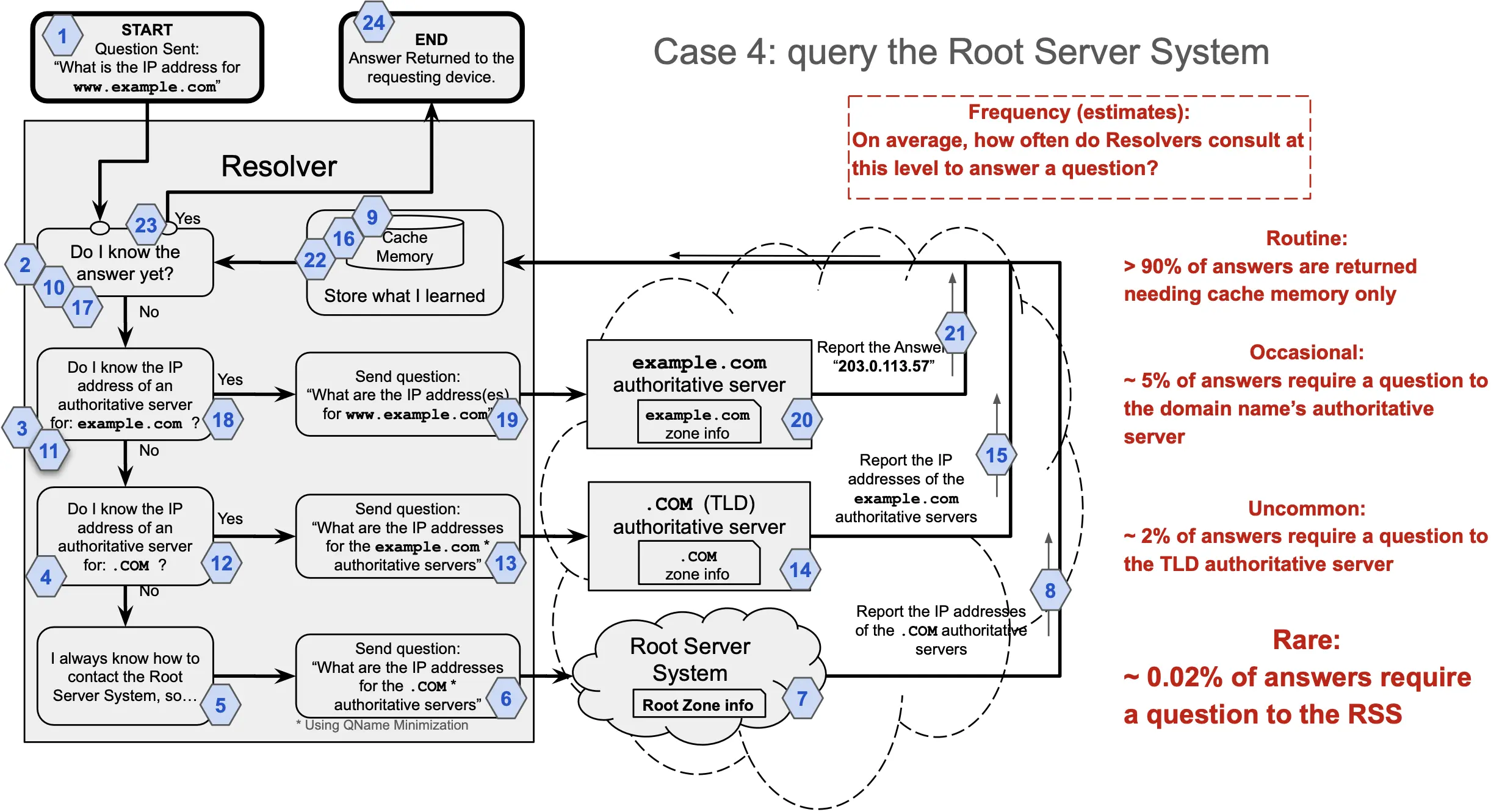
More than 90% of answers fall under Case 1, where the resolver has the final IP address in its cached memory. Approximately 5% of queries fall in Case 2, and approximately 2% fall into Case 3. Only one of every 5,000-10,000 queries, or about 0.02% of the total number of IP address requests, requires a question to the RSS.
The sole task of the RSS is to point queries from resolvers to the authoritative servers of all the Top-Level Domains on the Internet.
Thinking of the DNS in layers may help clarify it a bit:

There are three “layers” of things that a DNS query might ask, working in order from left to right in an Internet address (like www.example.com): what we call domain name zones, TLD zones, and the Root Zone.
To recap:
In the millisecond world of a resolver, queries to the Root Server System are rare.
Let’s look a little more closely at the Root Server System itself.
1. The RSS provides address information, not content.
The RSS answers one small part of an address question: “Can you give me the address of an authoritative server where I can look up the addresses of the Top-Level Domains?” The RSS does NOT offer content; it does not host websites or email or any other content, and it does not transmit or deliver any Internet content.
Takeaway: The Root Server System does not manage or carry any Internet content.
2. The RSS is not a “gatekeeper” to the Internet. It answers questions posed by address resolvers, in those rare instances when the address resolvers don’t already have the address answers in their cached memory.
Takeaway: Internet traffic is almost always transmitted without the need to interact with the Root Server System.
3. The RSS is stable, secure, and resilient.
From a technological standpoint: The RSS consists of more than 1800 globally distributed server instances, making it massively redundant. Each server instance holds 100% of the Root Zone information, and all these servers feature diverse hardware platforms, operating systems, DNS applications, and data routing.
Takeaway: The Root Server System has no single point of technological failure.
From an institutional standpoint: The RSS is jointly operated by 12 autonomous Root Server Operators (RSOs) around the globe. Each RSO is independent of the others, yet they continuously collaborate with each other. A force majeure event suffered by one RSO (such as a court injunction) has no operational impact on the others.
Takeaway: The Root Server System has no single point of institutional failure.
4. The RSS has operated since the 1980s and has never suffered a service blackout, although many online attackers have tried. The diversity of the system is its strength.
Takeaway: The Root Server System has a history of nearly 40 years of successful 24x7x365 operation.
5. Root Server Operators do not decide what appears in the Root Zone; they are simply a reliable, authenticated delivery method.
Takeaway: The Root Server System serves the TLD addresses provided by the TLD, IANA, and RZM.
The Root Server System underpins the Domain Name System, but actual queries to the RSS in normal Internet operations are extremely rare.
We hope this information has been useful. To watch a recording of my full presentation or download the slides, please visit: https://www.isc.org/presentations/
Sponsored byVerisign

Sponsored byWhoisXML API

Sponsored byVerisign

Sponsored byIPv4.Global

Sponsored byCSC

Sponsored byDNIB.com

Sponsored byRadix


A World-Renowned Source for Internet Developments. Serving Since 2002.