
Welcome:
Login
|
Sign Up
|
About CircleID
Follow:
|
|
|


|
||
|
||
In this article, I present an overview of a series of ‘proof-of-concept’ studies looking at the application of domain-name entropy as a means of clustering together related domain registrations, and serving as an input into potential metrics to determine the likely level of threat which may be posed by a domain.
In our previous studies, we utilised the mathematical concept of Shannon entropy1, providing a measure of the amount of information stored in a string of characters (or, equivalently, the number of bits required to optimally encode the string). The idea was applied to the second-level domain name (SLD) part of each domain (i.e. the portion of the domain name before the dot—such as ‘google’ in ‘google.com’), and broadly means that short domain names, or those with large numbers of repeated characters, will have low entropy values, whereas longer domain names, or those with large numbers of distinct characters, will have higher entropy.
The background to this analysis is the fact that domains registered for egregious purposes (such as spamming, malware distribution, or botnet creation) may be more likely to be registered in bulk by bad actors using automated algorithms2, which typically results in the generation of long, non-sensical (i.e. high entropy) domain names, which have the added benefit of not containing brand-related keywords and are typically therefore harder to detect using classic brand-monitoring techniques. The idea is that domains registered by a particular infringer for a specific campaign are likely all to be generated using the same algorithm, and may therefore have similar or identical entropy values.
In our initial proof of concept3, we considered the set of all domains registered on a particular day—a sample of around 205,000 domains. The advantage also of considering a set of domains with a common registration date is that it presents the possibility for one or more groups of automated bulk registrations (which are typically all registered at the same time) to be present.
Within the dataset, a range of domain entropy values was present, from a minimum of 0.000, to a maximum of 4.700, and with 92.3% of the dataset having values below 3.500. (see Figure 1). The top 1,000 highest-entropy domains (i.e. the top 0.49%) had entropy values in excess of 3.823, and accounted for the majority of examples which appeared visually to feature ‘random’ SLD strings. Within this high-entropy subset, a number of additional characteristics were indicative that many may have been registered for nefarious purposes, including the prominence of use of consumer-grade registrars and privacy-protection services, and the extent of the presence of active MX records amongst these new registrations (in 27.5% of the cases—indicating that these domains have been configured to be able to send and receive e-mails and therefore could potentially be associated with phishing activity).
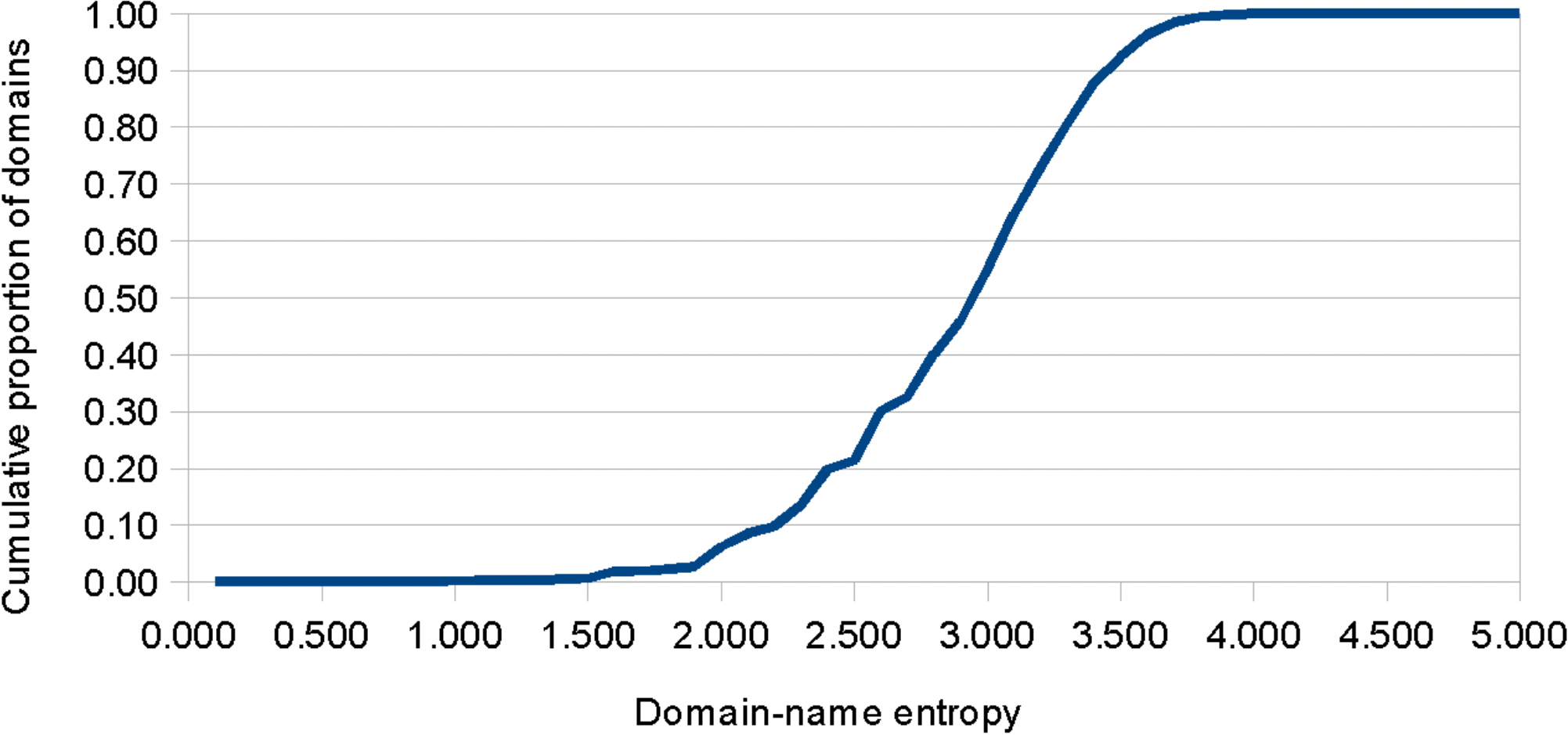
Indeed, at least one apparent ‘cluster’ of suspicious registrations was found to be present within the dataset, comprising a group of 125 .buzz (‘dot-buzz’) domains, all with an identical high entropy value (3.907), registered via a common registrar and associated with groups of similar IP addresses. At the time of analysis, many of the domains registered to Chinese-language, gambling-related websites, likely representing either an affiliate revenue generation scheme, or ‘dummy’ content serving to ‘mask’ higher-threat content which may only have been visible in specific geographic regions, or which may have been planned for subsequent upload.
In a follow-up study4, I considered a months’ worth of registrations of domains with names containing any of the top ten most valuable brands in 2022. Similarly, the high entropy domain names within this dataset included groups of apparently related, coordinated ‘clusters’ of domains, several of which appeared intended for fraudulent use and were consistent with registration via automated generation algorithms. For example, seven of the top eight domains in the dataset (by entropy values) had similar names of the form ‘google-site-verificationXXXXXX.com’ (or .net) (where ‘XXXXXX’ was a long string of apparently random characters), and a series of groups of ‘microsoft’ examples was identified, including keywords such as ‘cloudworkflow’, ‘netsuites’ and ‘cloudroam’.
Other studies taking similar approaches to the analysis of domain entropy also reach similar conclusions. For example, an analysis outlined in a blog posting by Tiberium5 states that the use of an entropy threshold of >3.1 (as an indicator of potential concern) correctly classifies 80% of NCSC malicious domains, and incorrectly classifies only 8% of the top 1000 most popular (legitimate!) domains overall (cf. Table 1).
| Domain name | Entropy value |
|---|---|
| google.com | 1.918 |
| youtube.com | 2.522 |
| facebook.com | 2.750 |
| twitter.com | 2.128 |
| instagram.com | 2.948 |
| baidu.com | 2.322 |
| wikipedia.org | 2.642 |
| yandex.ru | 2.585 |
| yahoo.com | 1.922 |
| whatsapp.com | 2.500 |
Additionally, an article published by Splunk7—looking at the entropy values of fully qualified domain names, i.e. also including subdomain names—also states that high-entropy examples are consistent with the use of domain generation algorithms, and may be indicative of association with malware (e.g. in ‘beaconing’) and other web exploits. Comparable approaches and conclusions can also be found in a range of other studies8, 9, 10, with some finding improvements in the reliability of threat determination through the use of alternative measures such as relative entropy (essentially, a comparison against the character distribution observed in a dataset of known legitimate domains, so as to provide a better measure of the randomness arising from automated algorithmic registrations)11.
Domain-name entropy analysis has applications in at least two key areas of brand protection. The first of these is the ability to ‘cluster’ together related infringements, which has a number of benefits, including the ability to identify serial infringers and instances of bad-faith activity, for targeted and effective bulk enforcement actions. The second key area is as an input into algorithms to quantify the likely level of threat which may be posed by an online feature such as a new domain registration. Threat determination is essential in allowing prioritisation of results for analysis, enforcement, or content-change tracking.
All other factors being equal, there is some indication that high-threat domains—particularly those associated with automated registrations by domain-name generation algorithms—may have a tendency to sit at the higher-entropy end of the spectrum (and, furthermore, that domain names generated using a particular algorithm may be likely to have similar entropy values). This statement runs alongside the assertion that legitimate domains may (in general) be more likely to have lower entropy values, particularly where there is a desire for legitimate businesses to utilise strongly branded, short, memorable web addresses—as can be seen in many of the globally most popular websites.
Sponsored byVerisign

Sponsored byCSC

Sponsored byIPv4.Global

Sponsored byDNIB.com

Sponsored byVerisign

Sponsored byRadix

Sponsored byWhoisXML API


A World-Renowned Source for Internet Developments. Serving Since 2002.