
Welcome:
Login
|
Sign Up
|
About CircleID
Follow:
|
|
|

|
||
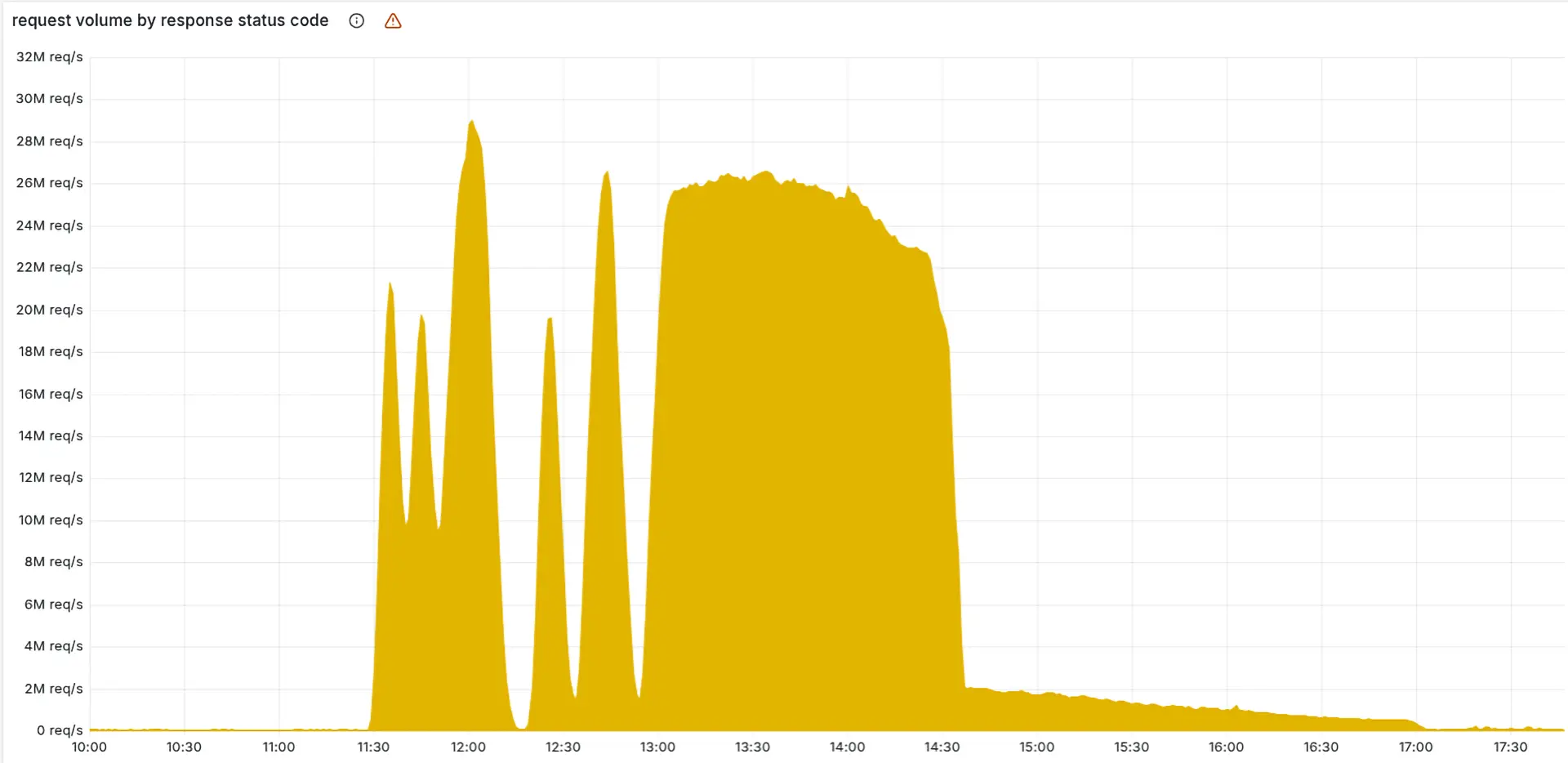
On November 18th, a major outage disrupted Cloudflare’s global network, making many of its core services unavailable for several hours. These services help protect and speed up websites. In a detailed post-mortem published that day, the company explained that a routine configuration update was the cause.
Misdiagnosed origin: The incident began at 11:20 UTC and was initially misdiagnosed as a distributed denial-of-service (DDoS) attack. In fact, the culprit was a flawed database permission change that led to malformed configuration files for Cloudflare’s Bot Management system. These files, larger than expected due to duplicated data, overwhelmed a size limit in the software, causing a cascade of failures in the company’s traffic-routing infrastructure.
The faulty file, propagated across Cloudflare’s servers, caused intermittent 5xx errors, elevated latency, and service disruptions in authentication (Turnstile), data storage (Workers KV), and access controls. Some users could not log in; others saw websites fail to load altogether.
Rollback resolution: Engineers eventually traced the failure to a query in the ClickHouse database cluster. By 14:30 UTC, they had rolled back the change, restored a known-good configuration file, and restarted affected services. Full recovery was confirmed by 17:06.
Cloudflare’s post, authored by CEO Matthew Prince, emphasizes that no malicious activity was involved and outlines steps to prevent recurrence—including stricter validation of internal configuration files and improvements to fault isolation in its core proxy system.
Bottom line: Given Cloudflare’s role as a linchpin of internet infrastructure, the outage drew attention beyond its immediate customers. The company’s transparency in documenting the failure is notable, though it also shows how a subtle internal change can ripple outward to disrupt a large portion of the web.
Sponsored byCSC

Sponsored byRadix

Sponsored byIPv4.Global

Sponsored byWhoisXML API

Sponsored byDNIB.com

Sponsored byVerisign

Sponsored byVerisign


A World-Renowned Source for Internet Developments. Serving Since 2002.