
Welcome:
Login
|
Sign Up
|
About CircleID
Follow:
|
|
|


|
||
|
||
The conversation around AI scraping has largely focused on copyright, with The New York Times v. OpenAI serving as the headline case. But while content creators worry about their words, the internet’s infrastructure providers are facing a much quieter, structural crisis.
Network operators and data hosts are currently subsidizing the training of third-party AI models. Every automated scrape request consumes bandwidth, compute, and egress capacity that the host pays for, often with zero return. What was once a marginal cost has, in the age of agentic AI, become a massive “free-rider” problem that threatens the economic viability of open data.
The root of this crisis isn’t technical; it’s legal. The LinkedIn v. hiQ Labs decision effectively stripped US companies of their primary defense against automated extraction, creating a “legal vacuum” where platform integrity is unenforceable.
To fix this, we don’t just need better firewalls. We need Congress to modernize the Computer Fraud and Abuse Act (CFAA) and establish a federal definition of “Data Misappropriation.”
For decades, companies relied on the CFAA to deter unauthorized automated agents. If an automated agent continued scraping after a cease-and-desist, it was effectively committing a federal crime. The hiQ decision broke this framework. It ruled that accessing publicly available data, even after explicit revocation, does not constitute “unauthorized access” under the CFAA. The court prioritized “openness,” but in doing so, it conflated human browsing with industrial-scale replication.
This has left infrastructure providers in a bind. We can block IPs (Layer 1 defense), but we have no legal recourse against persistent, adversarial actors who rotate proxies to evade detection. The law treats a bot extracting 10 million records the same as a human reading a single page.
This legal gap has birthed a “Free-Rider” economy. This risk is compounded by the rapid commercial expansion of scraping technologies, a market that Mordor Intelligence estimates already exceeds $1 billion and is projected to approach $2 billion by 2030.
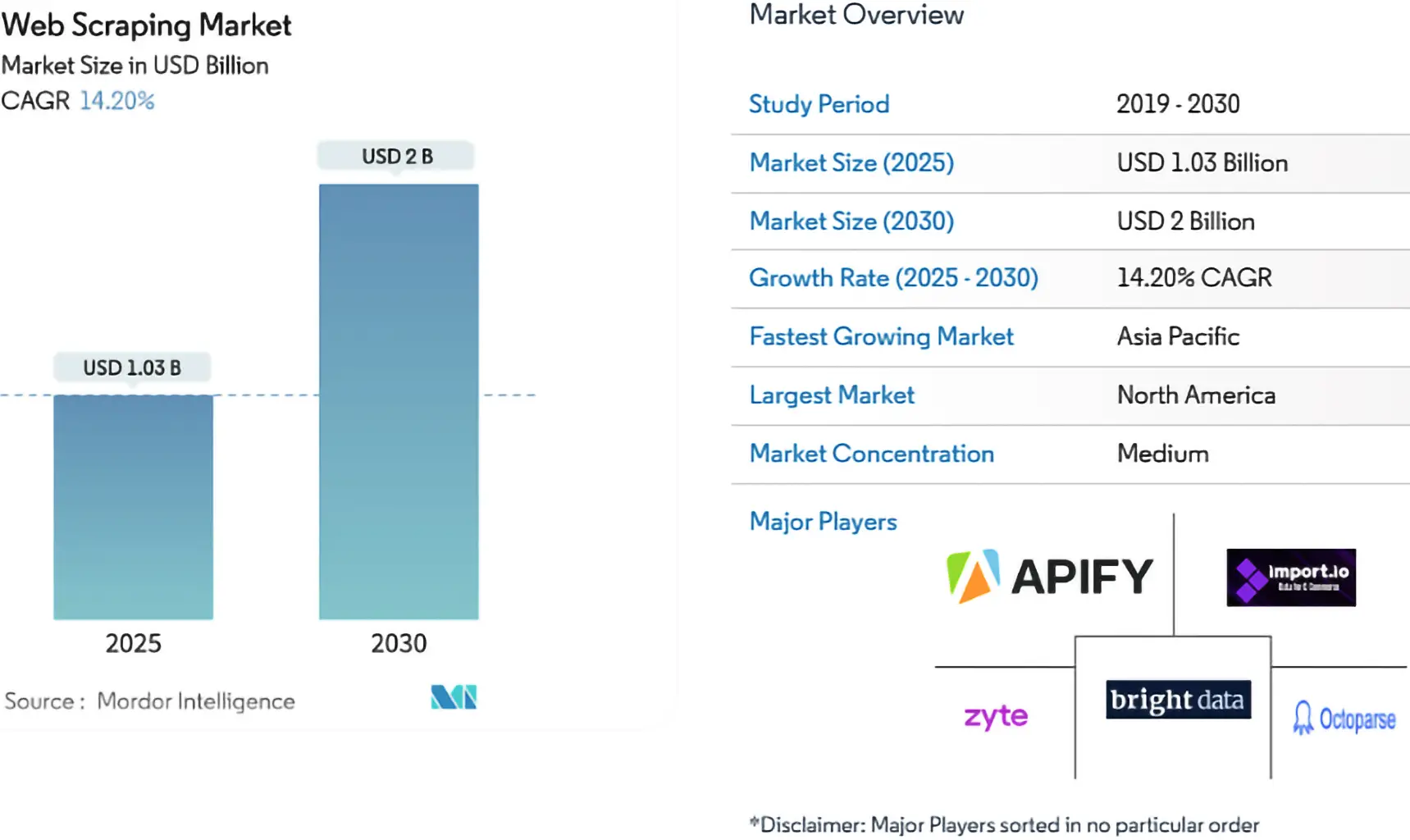
Unregulated scraping allows third parties to appropriate valuable, curated datasets without incurring the costs of generating or maintaining them.
This isn’t just “competition”; it is an infrastructure tax. When a scraping bot lifts a dataset, the host platform pays for the server load, the data cleaning, and the curation. The scraper captures 100% of the value while externalizing 100% of the cost. This dynamic disincentivizes investment in high-quality data infrastructure, creating a “Race to the Bottom” where platforms lock their doors not out of greed, but out of survival.
We cannot solve a structural economic problem with brittle technical defenses. To restore balance, the U.S. must move beyond the “Access” debate of the CFAA and adopt a property rights approach aligned with the 2025 OECD Guidelines.
Here is a 4-point legislative framework to close the gap:
We are currently asking security engineers to solve a policy failure. By relying solely on technical barriers like CAPTCHAs and fingerprinting, we are engaging in an endless arms race.
True platform integrity requires Governance. It requires Congress to recognize that data infrastructure is an asset class worthy of protection. By adopting a federal standard for Data Misappropriation, we can stop the “free-riding” economy and ensure that the next generation of AI is built on a foundation of fair exchange, not infrastructure theft.
Sponsored byVerisign

Sponsored byDNIB.com

Sponsored byCSC

Sponsored byVerisign

Sponsored byWhoisXML API

Sponsored byIPv4.Global

Sponsored byRadix


A World-Renowned Source for Internet Developments. Serving Since 2002.