
Welcome:
Login
|
Sign Up
|
About CircleID
Follow:
|
|
|


|
||
|
||
Domain name monitoring—that is, the detection of domains with names containing a brand-term (or other string) of interest—is a very well-established element of brand protection services. Branded domain names are of key importance to brand owners (as the basis for business-critical infrastructure (i.e. ‘core’ domain names), and as part of a ‘tactical’ portfolio of strategic and defensive registrations), but also to infringers, who can utilise domains as a means of impersonation, passing off, claimed affiliation, or traffic direction and monetisation. These types of third-party registrations are often of great concern by virtue of factors such as their explicit abuse of IP, and their high potential visibility in search engines. However, they are (up to a point) relatively straightforward to detect, through methods such as domain zone-file analysis, which most brand protection service providers will utilise as a standard methodology.
A more complex world is the ecosystem of subdomain names. A subdomain is the part of the URL prior to the dot preceding the domain name (e.g. ‘play’ in play.google.com). The owner of a domain name can create whatever hierarchy of subdomain names they wish, and can (for example) configure each distinct hostname (i.e. a subdomain plus domain-name combination) to resolve to a different IP address and webpage content. Additionally, some Internet service providers (‘private subdomain registries’) offer the sale of subdomains of one of more domains under their ownership, as a business model. Subdomains can be used legitimately for a range of different purposes, including the creation of subject- or region-specific microsites, but can be abused by infringers in many of the same ways as domain names1234. This issue is made more concerning by the fact that there is, in general, no comprehensive way of detecting potentially relevant subdomains (akin to the zone-file methods used for domain names themselves), which is one of the great unsolved issues in brand monitoring5.
Terminologically, ‘subdomain monitoring’ as a service description is often used in two distinct ways in the context of brand protection and cybersecurity. The first—most usually carried out by the registrar responsible for the management of a brand owner’s official domain portfolio, and therefore with a full overview of their domain and subdomain infrastructure—refers to the monitoring of subdomains of the brand owner’s official domains, with a view to identifying potential cybersecurity issues. These can take the form of ‘dangling’ DNS records—i.e. subdomains which are no longer used and which are susceptible to hijacking—or the third-party creation of new subdomains through DNS compromise (i.e. domain ‘shadowing’). The second definition—i.e. the identification of relevant subdomains on an arbitrary third-party domain name, a process which may be termed subdomain ‘discovery’—is a much more complex prospect. Generally it involves the application of a combination of methods (which even together are not comprehensive), such as analysis of domain-name zone configuration information (e.g. passive DNS analysis), certificate transparency (CT) analysis, or the use of explicit queries for specific subdomain names. This issue of subdomain discovery is the focus of the remainder of this article.
As a case study, we explore an approach allowing the identification of (as many as possible) subdomains of each of the top 50 most popular website domain names (as of March 2024), according to Similarweb6, using a combination of monitoring and discovery scripts789, open-source databases, and search queries.
i. Methodology
In general, a comprehensive overview of the subdomains of a particular domain name is only possible via inspection of the full DNS zone record, which is generally only accessible by the managing registrar (as for a (true) subdomain monitoring service). However, partial coverage—from a discovery point of view—can be achieved through a combination10 of:
ii. Terminology
In the description of the identified subdomains, the following terminology is used (in reference to test.mail.site.com as an example):
Using the range of approaches discussed above, over 640,000 unique subdomains were identified, across just the 50 domain names under consideration (Figure 1).
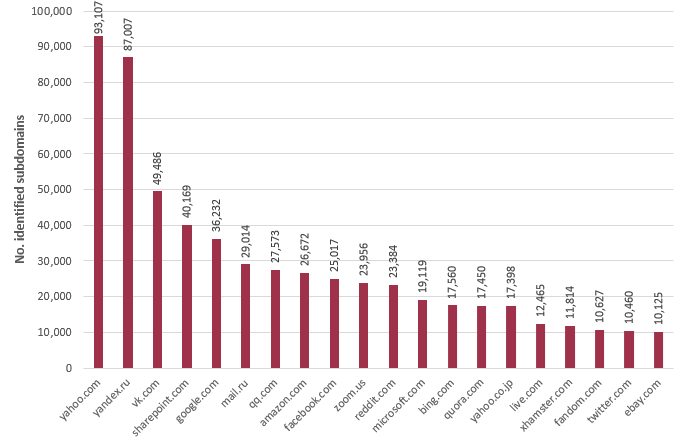
The subdomain names range in length and number of levels, up to 231 characters and 28 levels (respectively), with the longest subdomain in the dataset (by both measures) found to be:
news.xinhuanet.comwww.zalando.dewww.google.
comhyperboleandahalf.blogspot.comchannel.pixnet.netwww.youtube.
comhistory.gmw.cnvk.comwww.bing.comsd.360.cnmarketplace.asos.
comstock.sohu.com2kindsofpeople.tumblr.comimgur.comgithub.
comwww.xvideos.com
The distribution of lengths (up to 50 characters) and numbers of levels (up to 10) across the whole dataset is shown in Figure 2.
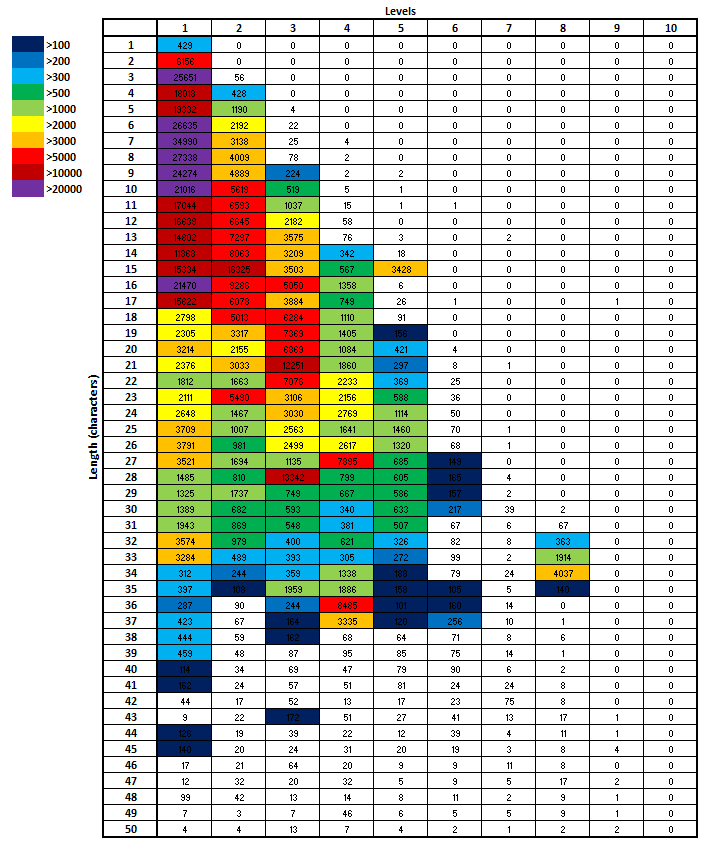
For one-level subdomains, there is a peak in number of instances at a length of 7 characters. For two-level subdomains, there is a peak at 15 characters (i.e. a mean of 7.0 characters per element), and for three-level subdomains the peak occurs at length 21 (mean = 6.3 characters per element).
From the overall dataset, it is possible to calculate the statistics for the most frequently occurring subdomain elements, regardless of the level in the subdomain hierarchy at which they appear. This information is shown in Table 1.
| Subdomain element | No. instances |
|---|---|
| 25,111 | |
| ne1 | 18,229 |
| gq1 | 17,753 |
| bf1 | 16,241 |
| ghs | 15,801 |
| aa-rt | 15,037 |
| qzone | 13,855 |
| corp | 12,552 |
| afd | 12,436 |
| clump | 11,669 |
Other key terms appearing in the top 100 include ‘www’ (5,707 instances), ‘teams’ (3,897), ‘dns’ (1,879), ‘shop’ (1,547), ‘cloud’ (1,477), ‘dev’ (1,331), ‘extranet’ (1,261), ‘test’ (1,145), ‘sandbox’ (1,084), ‘search’ (960) and ‘media’ (873).
It is also possible to calculate more granular statistics for elements appearing at key locations in the subdomain strings. Tables 2 and 3 show the top third-level domain strings (i.e. the element immediately preceding the domain name) and lowest-level domain strings (i.e. the element at the start of the subdomain name string) identified across the dataset, by total numbers of instances (noting that, for subdomains with one level, the third-level string will—by definition—also be the lowest level).
| Third-level domain | No. instances |
|---|---|
| ne1 | 18,225 |
| gq1 | 17,745 |
| bf1 | 16,188 |
| ghs | 15,785 |
| aa-rt | 15,037 |
| qzone | 13,853 |
| ynwp | 7,307 |
| corp | 6,910 |
| sg3 | 6,870 |
| spaces | 6,185 |
| Lowest-level domain | No. instances |
|---|---|
| lo0 | 11,536 |
| www | 4,086 |
| ha1 | 993 |
| ha2 | 903 |
| m | 776 |
| api | 753 |
| o-o | 698 |
| crawl | 661 |
| vl-120 | 522 |
| a | 418 |
Certain classes of subdomain names also tend to have special use-cases—two-character names, for example, are often used to denote country codes (e.g. for regional subsites) or may have other special meanings (e.g. ‘go’, ‘my’ or ‘ai’). The top 20 two-character subdomain elements across the whole dataset are shown in Table 4.
| Subdomain element | No. instances |
|---|---|
| 98 | 3,512 |
| a1 | 2,352 |
| ke | 1,916 |
| 10 | 1,817 |
| qa | 1,750 |
| bb | 1,517 |
| dv | 1,206 |
| sc | 1,112 |
| ny | 1,020 |
| tc | 841 |
| a0 | 690 |
| a2 | 685 |
| in | 652 |
| hk | 568 |
| mp | 561 |
| cp | 524 |
| fp | 523 |
| 522 | |
| my | 502 |
| db | 491 |
Various other common abbreviations also appear highly in the dataset, including the (potential) country codes de (430 instances), ru (343), fr (324), us (252), cn (246), es (246), it (243), kr (243), uk (223), au (200), jp (191), and other terms such as go (393).
It is worth noting, however, that the above statistics may be dominated by the naming style used across just a small number of sites. For example, all of the ‘ne1’ third-level domains were identified on the yahoo.com site. Potentially a more meaningful insight into the style of names used across the subdomain landscape generally can be gained by determining the numbers of unique sites (within the dataset of 50) across which a specific name string was identified. These statistics—for the features shown in Tables 2 and 3—are shown in Tables 5 and 6.
| Third-level domain | No. sites (/ 50) |
|---|---|
| www | 49 |
| m | 43 |
| api | 40 |
| support | 36 |
| blog | 35 |
| 34 | |
| help | 33 |
| dev | 31 |
| news | 31 |
| 30 |
| Lowest-level domain | No. sites (/ 50) |
|---|---|
| www | 49 |
| m | 44 |
| api | 43 |
| dev | 40 |
| 39 | |
| support | 39 |
| blog | 37 |
| help | 36 |
| test | 35 |
| app | 34 |
Several of these terms have clear use-cases, and appear to be used consistently across multiple popular sites (e.g. the use of ‘m.’ for the mobile-compatible version of a website).
Many of these trends mirror those from previous studies. For example, a 2021 analysis11 of the most popular subdomain (‘element’) strings overall found that the top three were ‘www’, ‘mail’ and ‘forum’. Whilst ‘www’ does not appear in the list of top ten most frequently occurring subdomain elements across the 50 sites considered in this analysis (Table 1), it does appear more than 5,700 times across the dataset. Furthermore, the dataset contains almost 1,000 distinct variants of ‘www’ being used as subdomain elements, with the list topped by ‘www’ itself (5,707 instances), followed by ‘comwww’ (146), ‘www2’ (42), ‘www1’ (31) and ‘ww’ (24).
An additional study12, looking at the (analogous) use of second-level domain names in conjunction with dot-brand extensions, also found extensive use of many of the strings featured in this study, including ‘mail’ and ‘api’.
It was noted previously that subdomain-related brand abuse can be a popular way of creating infringements or deceptive content. As a proxy for the infringement landscape, we can consider just those examples from the 50-site dataset in which the name of the Apple brand (the most valuable brand in 202413, but whose website does not appear in the list of 50 considered) appears anywhere in the subdomain name string. This will represent just a tiny proportion of the potential subdomain infringement landscape, since we are focusing just on a single brand, are considering only those instances where a textual mention appears in the subdomain name, and are focusing only on subdomains on the top 50 sites (where—one might hope—being controlled by large corporations and, in some cases, with IP protection programmes in place, the infringement landscape may be much less pronounced than across the Internet generally). In addition, the searches carried out for this study did not include any explicit brand-related searches; in a formal landscape sweep for (say) Apple, it would be advantageous to include additional search queries of the form: site:[site.com]+apple.
Nevertheless, the study dataset includes 139 examples in which ‘apple’ is referenced somewhere in the subdomain name, including a small number of live examples of potential infringements (Figure 3).
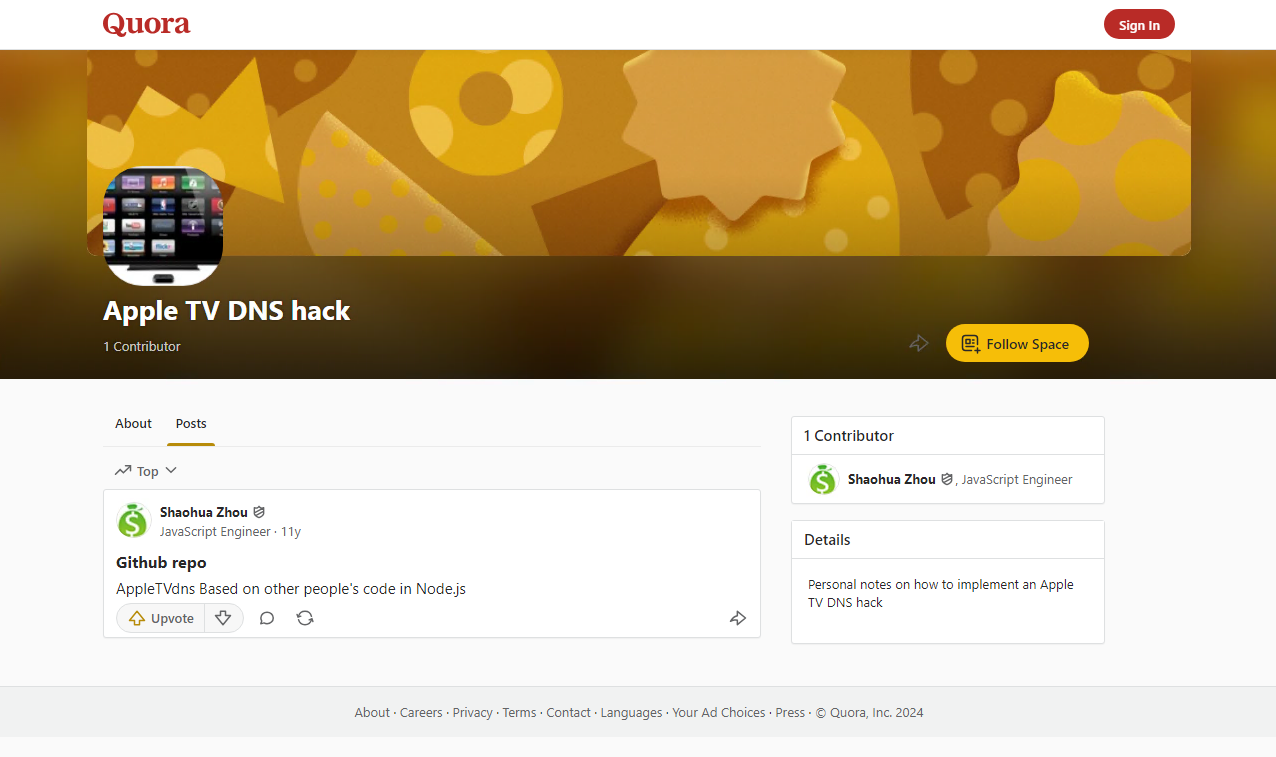
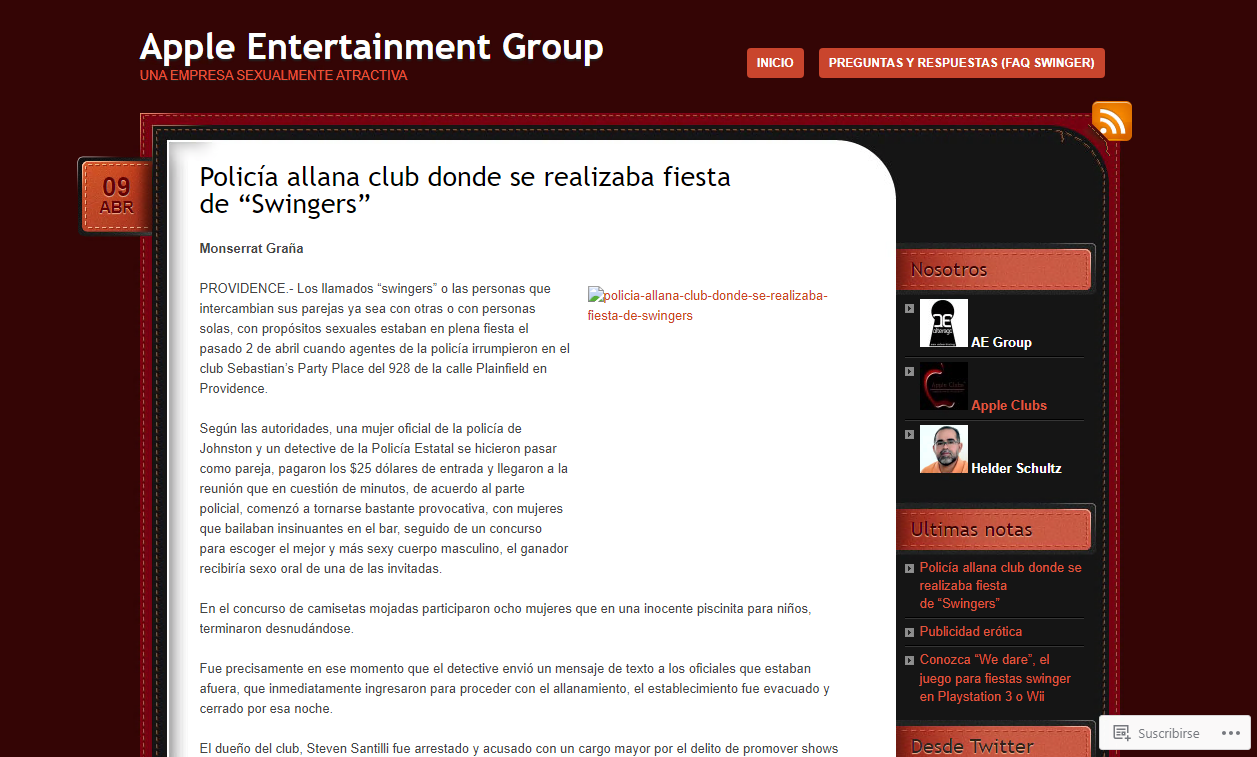
Aside from the specific trends observed in the set of subdomains of the top 50 most popular websites, a significant take-away from this analysis is the effectiveness of the use of a range of discovery techniques to identify relevant content. Using a combination of search-engine queries, information from DNS, SSL and certificate transparency databases, and brute-force keyword-based searches, it has proven possible to identify almost two-thirds of a million subdomains of the 50 websites in question.
Given the risks associated with subdomain-based infringements, monitoring of this space as part of a comprehensive brand protection solution is of key importance, but has always proven difficult to achieve. This initial analysis shows that the range of available approaches can, when used together, provide a successful means of detecting potential threats. Whilst completely comprehensive subdomain detection is unlikely to be possible, these methods certainly provide a significant step in the right direction.
Sponsored byIPv4.Global

Sponsored byCSC

Sponsored byRadix

Sponsored byVerisign

Sponsored byWhoisXML API

Sponsored byDNIB.com

Sponsored byVerisign


A World-Renowned Source for Internet Developments. Serving Since 2002.